An article by the Allen Institute for AI (AI2) highlights a pending issue: machines do not understand (really like humans) what they write or read.
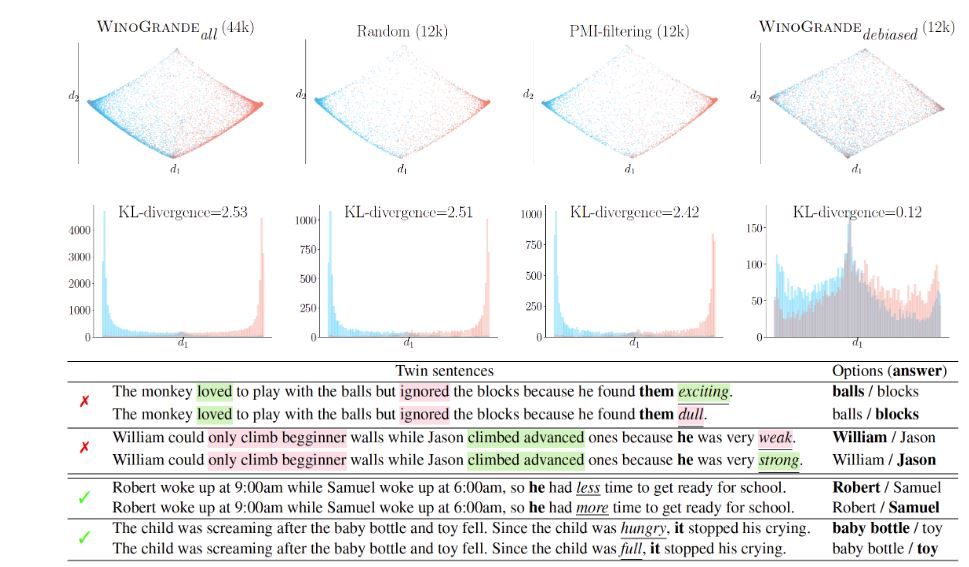
«The Winograd Schema Challenge (WSC) (Levesque, Davis, and Morgenstern 2011), a benchmark for commonsense reasoning, is a set of 273 expert-crafted pronoun resolution problems originally designed to be unsolvable for statistical models that rely on selectional preferences or word associations. However, recent advances in neural language models have already reached around 90% accuracy on variants of WSC. This raises an important question whether these models have truly acquired robust commonsense capabilities or whether they rely on spurious biases in the datasets that lead to an overestimation of the true capabilities of machine commonsense. To investigate this question, we introduce WinoGrande, a large-scale dataset of 44k problems, inspired by the original WSC design, but adjusted to improve both the scale and the hardness of the dataset. The key steps of the dataset construction consist of (1) a carefully designed crowdsourcing procedure, followed by (2) systematic bias reduction using a novel AfLite algorithm that generalizes human-detectable word associations to machine-detectable embedding associations. The best state-of-the-art methods on WinoGrande achieve 59.4-79.1%, which are 15-35% below human performance of 94.0%, depending on the amount of the training data allowed. Furthermore, we establish new state-of-the-art results on five related benchmarks – WSC (90.1%), DPR (93.1%), COPA (90.6%), KnowRef (85.6%), and Winogender (97.1%). These results have dual implications: on one hand, they demonstrate the effectiveness of WinoGrande when used as a resource for transfer learning. On the other hand, they raise a concern that we are likely to be overestimating the true capabilities of machine commonsense across all these benchmarks. We emphasize the importance of algorithmic bias reduction in existing and future benchmarks to mitigate such overestimation». Source: https://arxiv.org/abs/1907.10641
WinoGrande is a new collection of Winograd Schema Challenge (WSC) problems that are adversarially constructed to be robust against spurious statistical biases. While the original WSC dataset provided only 273 instances, WinoGrande includes 43,985 instances, half of which are determined as adversarial. Key to our approach is a new adversarial filtering algorithm AfLite for systematic bias reduction, combined with a careful crowdsourcing design. Despite the significant increase in training data, the performance of existing state of the art methods remains modest (61.6%) and contrasts with high human performance (90.8%) for the binary questions. In addition WinoGrande allows to use transfer learning for achieving new state of the art results on the original WSC and related datasets. Finally it discuss how biases lead to overestimating the true capabilities of machine commonsense. Source: https://mosaic.allenai.org/projects/winogrande
The work «WinoGrande: An Adversarial Winograd Schema Challenge at Scale» suggests a new perspective for designing benchmarks for measuring progress in AI. Unlike past decades where the community constructed a static benchmark dataset to work on for many years to come, we now need AI algorithms to compose challenges that are hard enough for AI, which requires dynamic datasets that evolve together with the evolving state of the art. (Source: https://arxiv.org/pdf/1907.10641.pdf)
URL: http://winogrande.allenai.org
PDF arxiv: https://arxiv.org/pdf/1907.10641.pdf
Github (Codebase): https://github.com/allenai/winogrande
Download WinoGrande Dataset V1.1 Beta: https://storage.googleapis.com/ai2-mosaic/public/winogrande/winogrande_1.1_beta.zip
Liked this post? Follow this blog to get more.